모델과 학습에 대한 개념이 안 잡히신 분들은 딥러닝과 경사 하강법를 참고하시기 바랍니다.
Overfitting, Underfitting 개념
- 정의 : 기계 학습(machine learning)에서 학습 데이타를 과하게 학습(overfitting)하는 것
일반화와 반대로 학습 데이터가 부족하거나 데이터의 경향을 찾아낼만큼 충분히 학습되지 않을 경우 나타나는 현상을 언더피팅(underfitting)이라고 합니다.
아래 그림을 보면 데이터 경향에 따라 대~충 그린 듯한 검은색 라인으로보다 완벽하게 구별해낸 초록색 라인을 가진 모델이 더 좋은 것 같습니다. 정말 그럴까요?

공이 무엇인지 알아내는 로봇을 학습시키려고 합니다. 먼저, 공은 야구공, 농구공, 축구공처럼 동그랗게 생긴 것이야~ 라고 가르칠 것입니다.

이 공들을 그대로 학습한 로봇에게 Test 해봅니다.



가르쳐준대로 잘 답하는 군요.
그런데 학습하지 않았던 공과 모양이 비슷한 애들을 던져주니 이것도 공이라고 판단해버립니다.


그래서 이번엔 사과, 달은 공이 아니야~ 라고 가르쳐주니 사과, 달은 공이 아니라고 제대로 예측은 했지만 새로 입력받은 골프공, 탁구공도 공이 아니라고 해버리네요.

이처럼 많은 공통특성 중 일부 특성(동그란 것은 공이다)만 반영돼서 새로운 데이터도 막 예측해버리는 모델을 Underfitting되었다, 공통 특성 이외에 세부 특성(동그랗지만 사과처럼 윤기나는 것, 동그랗지만 달처럼 표면이 울퉁불퉁한 것은 공이 아니다)까지 반영하여, 새로운 데이터에 대해서는 예측하지 못하는 모델을 Overfitting되었다고 합니다.
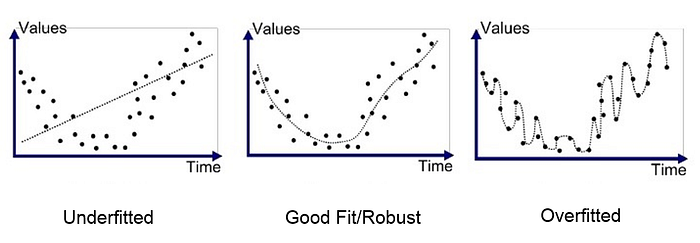
Underfitting처럼 일부 특성만 반영하는 이유는 공의 다양성이 적어 variance(분산)가 낮아 한쪽으로 취우침 현상(bias가 높음)이 있기 때문입니다. 그리고 Overfitting처럼 세부 특성만 반영하여 새로운 특성을 반영을 못하는 이유는 공이 다양하지만(variance가 높음) 학습한 것 이외에는 그 어떤 것도 주관을 잘 내세우지 못하는 현상(bias가 낮음)이 있기 때문입니다.
그래프로 그려보면 다음과 같습니다.

조기 종료(Early stopping)
underfit과 overfit 사이에서 어떤 지점에서 학습을 끊어야 제대로 된 모델을 얻을 수 있을까요? 바로 error가 낮은 중간지점입니다.

이처럼 이전 epoch 때와 비교해서 오차가 증가했다면 학습을 중단한다는 개념이 조기 종료(Early stopping)입니다. 어떤 일정한 epoch 수를 거듭하면서 계속해서 오차가 증가하면 학습을 중단한다’는 방식으로 구현하여 적절히 학습을 적절히 끊어주면 최적의 모델을 얻을 수 있습니다.
모델 복잡도와의 관계
데이터에 비해서 모델이 너무 간단하면 언더피팅(underfitting)이 발생하고, 모델을 너무 복잡하게 선택하면 오버피팅(overfitting)이 발생합니다. 데이터에 대한 모델을 적절한 복잡성을 선택하는 것이 오버피팅(overfitting)과 언더피팅(underfitting) 문제를 피하는 방법 중에 하나입니다.

ref
https://nittaku.tistory.com/289
https://medium.com/greyatom/what-is-underfitting-and-overfitting-in-machine-learning-and-how-to-deal-with-it-6803a989c76
https://forensics.tistory.com/29
https://ko.d2l.ai/chapter_deep-learning-basics/underfit-overfit.html