저희는 이전 포스트를 통해
‘손실 함수’란
- 예상한 값과 실제 타깃값의 차이
를 함수로 정의한 것이라는 것을 알게 되었습니다. 이 함수는 학습이 잘 되게 하는 하나의 지표입니다. 경사하강법이 이 손실 함수의 값을 최소화시키는 방법으로 가중치를 구하기 때문이죠. 제 말이 이해가 안가신다면 딥러닝과 경사 하강법을 참고하시기 바랍니다.
그렇다면 활성화 함수도 손실 함수처럼 또 하나의 학습이 잘 되게 하는 함수일까요? 정의를 보도록 하죠.
‘Activation function’ 활성화 함수.
- 정의 : 입력 신호의 총합을 출력 신호로 변환하는 함수
딥러닝과 경사 하강법에서 ‘딥러닝은 문제를 대충 추론해서 정답이랑 비교했을 때 얼마나 다른지(오차)를 계산에서 그걸 가중치라는 것에 넣고 다음문제를 풀 때 반영한다’ 라고 했습니다. 여기서 다음 문제를 풀 때 어떻게 반영한다는 것일까요? 여기서 퍼셉트론(perceptron)을 짚고 넘어가야 할 것 같습니다.
퍼셉트론
퍼셉트론은 아래 그림과 같이 다수의 신호(Input)을 입력받아서 하나의 신호(Output)을 출력하는 구조의 알고리즘입니다.
x1과 x2는 입력 신호, y는 출력 신호, w1과 w2는 가중치를 의미합니다. (w : weight) 입력 신호가 다음으로 보내질 때는 각각 고유한 가중치가 곱해지고 그 값들을 모두 더했을 때 어떠한 임계값(θ)을 넘을 때만 1로 출력합니다. 단순히 임계값(θ)을 넘으면 1, 아니면 0으로 출력할 수도 있지만(이건 계단 함수) 더 나아가 좀 더 복잡한 방식을 적용해서 출력할 수도 있습니다. 이처럼 입력 신호의 총합을 출력 신호로 변환하는 함수를 활성화 함수라고 합니다.

활성화 함수의 종류
- 계단 함수 (step function)
- 퍼셉트론에서 사용된 활성화 함수이며, 단순히 임계값(θ)을 넘으면 1, 아니면 0으로 출력합니다.
- 퍼셉트론에서 사용된 활성화 함수이며, 단순히 임계값(θ)을 넘으면 1, 아니면 0으로 출력합니다.
- 시그모이드 함수 (sigmoid function)
- 자연 상수 e가 지수 함수에 포함되어 분모에 들어가며 신경망 초기 모델에 많이 사용하던 활성화 함수입니다.
- 자연 상수 e가 지수 함수에 포함되어 분모에 들어가며 신경망 초기 모델에 많이 사용하던 활성화 함수입니다.
- 하이퍼볼릭 탄젠트 (hyperbolic tangent function)
- 자연 상수 e가 지수 함수에 포함되어 분모에 들어가며 신경망 초기 모델에 많이 사용하던 활성화 함수입니다.
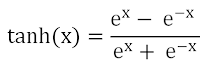
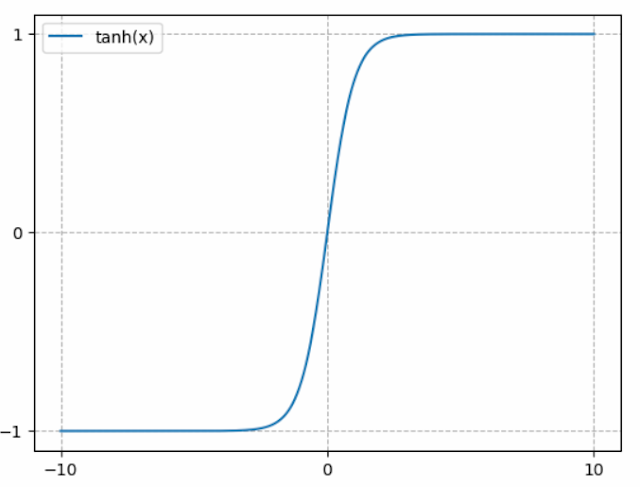
- 자연 상수 e가 지수 함수에 포함되어 분모에 들어가며 신경망 초기 모델에 많이 사용하던 활성화 함수입니다.
- ReLU 함수
- 식과 그래프로 보아도 굉장히 단순하며 시그모이드나 하이퍼볼릭 탄젠트 함수가 특정 값에 가까워질수록 미분값이 0으로 소실 되버리는 ‘Vanishing gradient 현상’을 해결하기 위한 활성화 함수입니다.
- Vanishing gradient 현상 : RNN의 탄생 참고
- Vanishing gradient 현상 : RNN의 탄생 참고
- 식과 그래프로 보아도 굉장히 단순하며 시그모이드나 하이퍼볼릭 탄젠트 함수가 특정 값에 가까워질수록 미분값이 0으로 소실 되버리는 ‘Vanishing gradient 현상’을 해결하기 위한 활성화 함수입니다.






활성화 함수의 목적
활성화 함수가 입력 신호의 총합을 출력 신호로 변환해준다고는 하는데 이렇게 해서 얻을 게 뭐가 있을까요? 바로 Data를 비선형으로 바꾸기 위해서입니다. 이전 포스트에서 배운 Linear regression을 적용하기엔 현실적으로 어려운 Data들이 많습니다. 항상 Data의 분포가 선형이 아니기 때문이죠.
왜 어려운지는 ‘XOR 게이트 표현을 못하기 때문’인데 이 링크로 들어가보시면 자세히 설명되어 있으니 참고하시기 바랍니다.
비선형 함수의 장점
우리는 신경망을 깊이 쌓아 모델의 성능을 높이는데, 이 때 활성화함수는 꼭 비선형 함수이어야 합니다. 선형 함수를 사용하면 신경망의 층을 깊게 쌓는 것에 의미가 없어지기 때문입니다.
y = ax
라는 선형함수가 있다고 한다면 이 것을 3층으로 구성하면
y = a(a(a(x)))
와 동일한 것으로 이는
y = a3(x)
와 같습니다. 굳이 은닉층 없이 선형함수로 네트워크를 구성하는 것은 의미가 없다는 뜻입니다.
- 참고로 층을 쌓아서 신경망을 구축하게 되면, 깊게 쌓을수록, 선형의 한계를 벗어나 비선형, 특이한 모형들에 대해 분류를 잘 할 수 있게 됩니다.
ref
https://leedakyeong.tistory.com/entry/%EB%B0%91%EB%B0%94%EB%8B%A5%EB%B6%80%ED%84%B0-%EC%8B%9C%EC%9E%91%ED%95%98%EB%8A%94-%EB%94%A5%EB%9F%AC%EB%8B%9D-%ED%99%9C%EC%84%B1%ED%99%94%ED%95%A8%EC%88%98%EB%9E%80-What-is-activation-function
https://leedakyeong.tistory.com/entry/%EB%B0%91%EB%B0%94%EB%8B%A5%EB%B6%80%ED%84%B0-%EC%8B%9C%EC%9E%91%ED%95%98%EB%8A%94-%EB%94%A5%EB%9F%AC%EB%8B%9D-%ED%8D%BC%EC%85%89%ED%8A%B8%EB%A1%A0%EC%9D%B4%EB%9E%80-What-is-perceptron
https://m.blog.naver.com/PostView.nhn?blogId=worb1605&logNo=221187949828&proxyReferer=https:%2F%2Fwww.google.com%2F
https://sacko.tistory.com/17
http://cbjsena.blogspot.com/2018/
Previous
손실 함수와 경사 하강법의 관계
go to -> Previous